Google製の多言語OCRエンジンを搭載した「Softi FreeOCR」
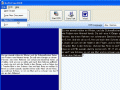
「Softi FreeOCR」は、スキャナや画像ファイルから読み込んだ画像上の文字を認識してテキストデータに変換するOCR(Optical Character Recognition:光学文字認識)ソフトだ。Googleがオープンソースで開発しているTesseract free OCR engineという認識エンジンを使用している。他言語に対応しており、今の所英語、フランス語、イタリア語、オランダ語、スペイン語、ドイツ語の認識が可能。日本語には対応していないが、Googleのことだから今後対応してくれるかも知れないぞ。とりあえず、外国語の教科書をスキャンして認識し、Googleの翻訳に突っ込むといった使い方にでもどうぞ。
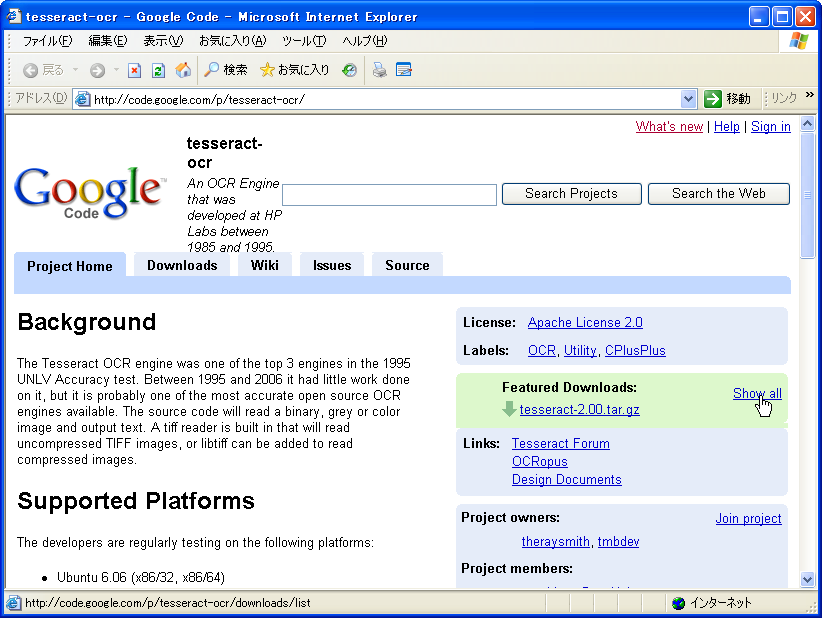
本体には英語のデータしか同梱されていない。他の言語を認識するには、http://code.google.com/p/tesseract-ocr/に行って、ダウンロードリンクの「Show all」からTesseractOCRプロジェクトのファイル一覧ページを開こう。
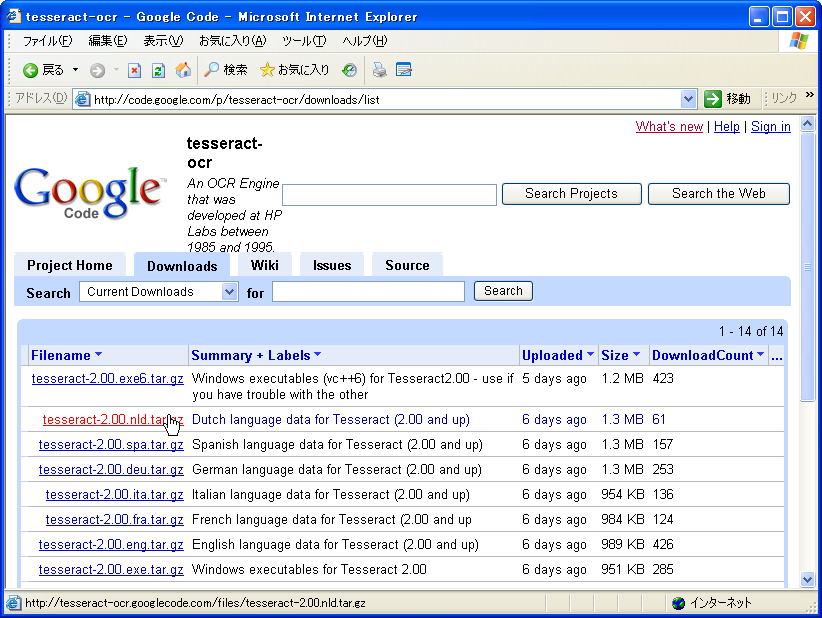
言語定義ファイルへのリンクがあるので、認識させたい言語のリンクをクリックしてダウンロードする。.tar.gz形式の解凍できるアーカイバで解凍しよう。
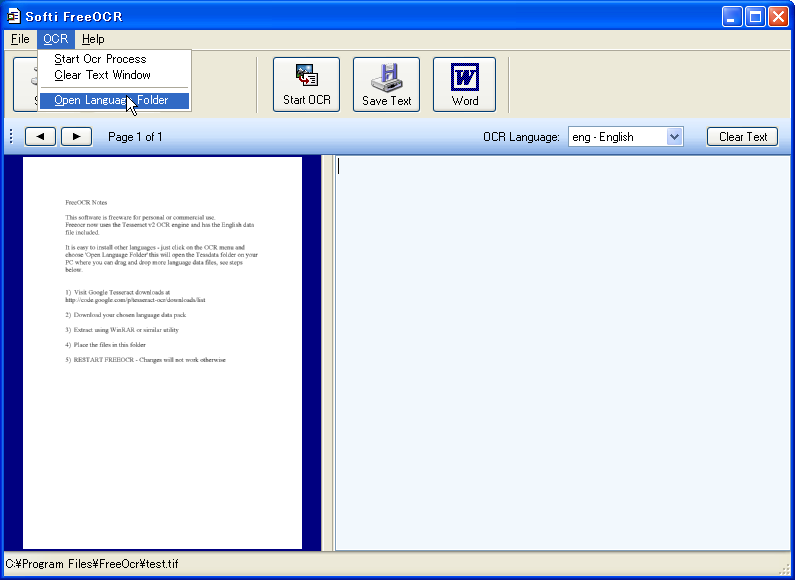
Softi FreeOCRをインストールして起動したら、メニューの「OCR」→「Open Language Folder」を実行。
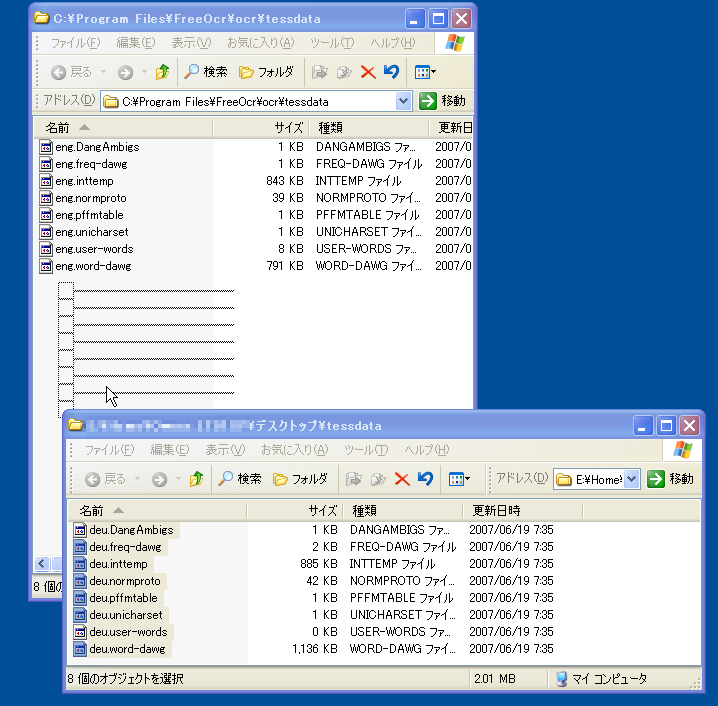
言語ファイルのフォルダが表示されるので、先ほどダウンロードしたアーカイブの中の言語ファイルをコピーすれば、言語定義ファイルのインストールが完了する。
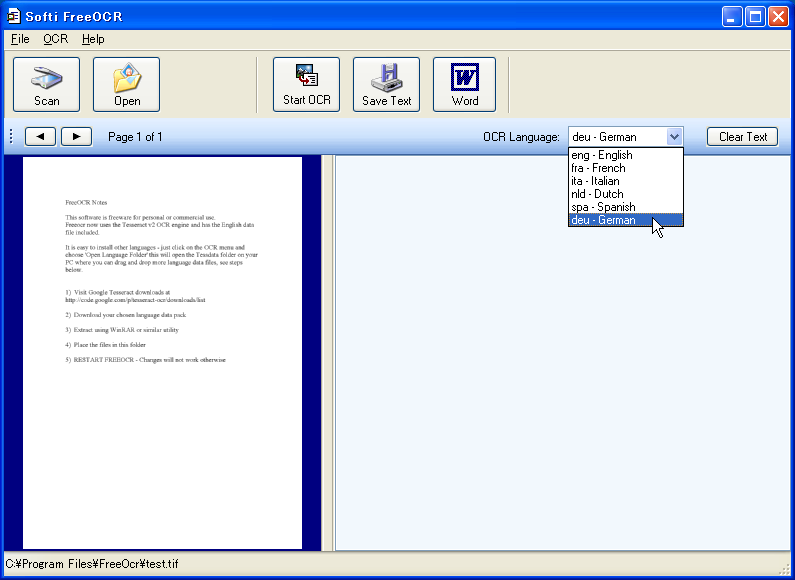
一旦Softi FreeOCRを再起動して、「OCR Language」の欄で言語を選択しよう。
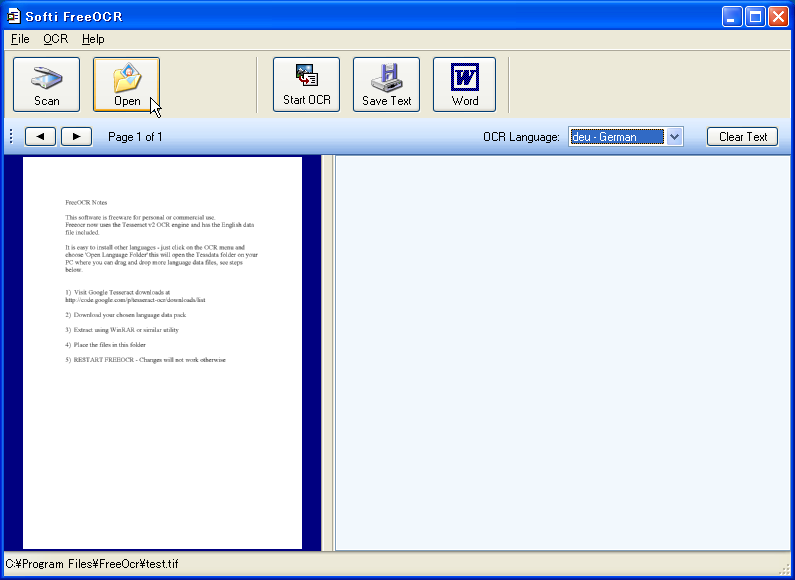
「Scan」でスキャナから画像を読み込むか、「Open」で画像ファイルを読み込む。
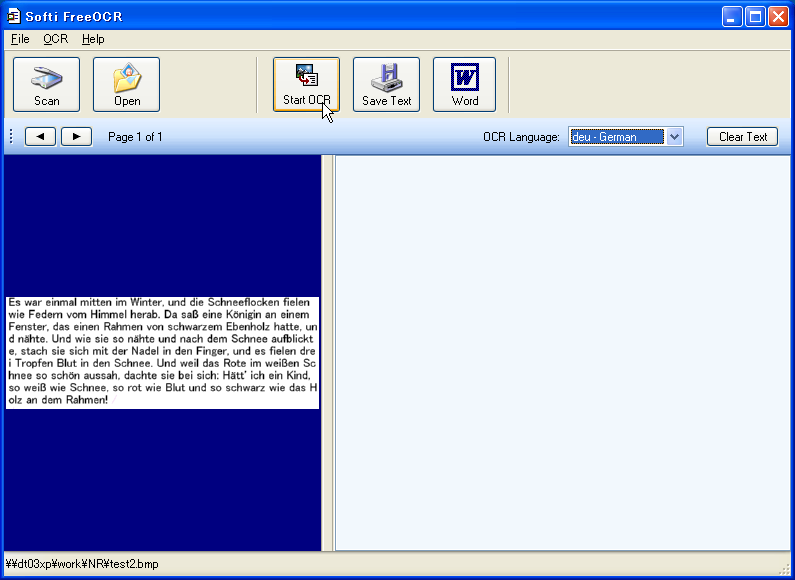
「Start OCR」を押せば、文字認識が始まる。
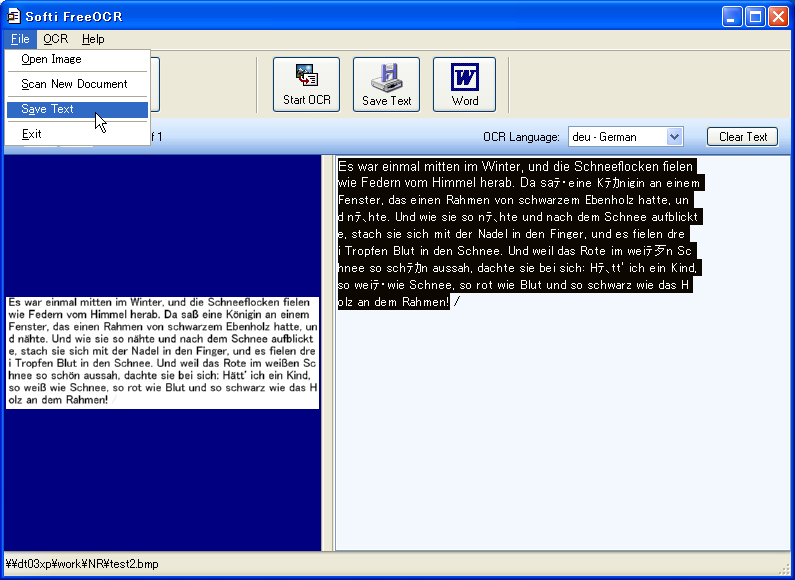
右側に認識結果が表示される。ドイツ語のウムラウトなどは文字化けして表示されるが、メニューの「File」→「SaveText」で保存すれば正しく表示できるようになる。
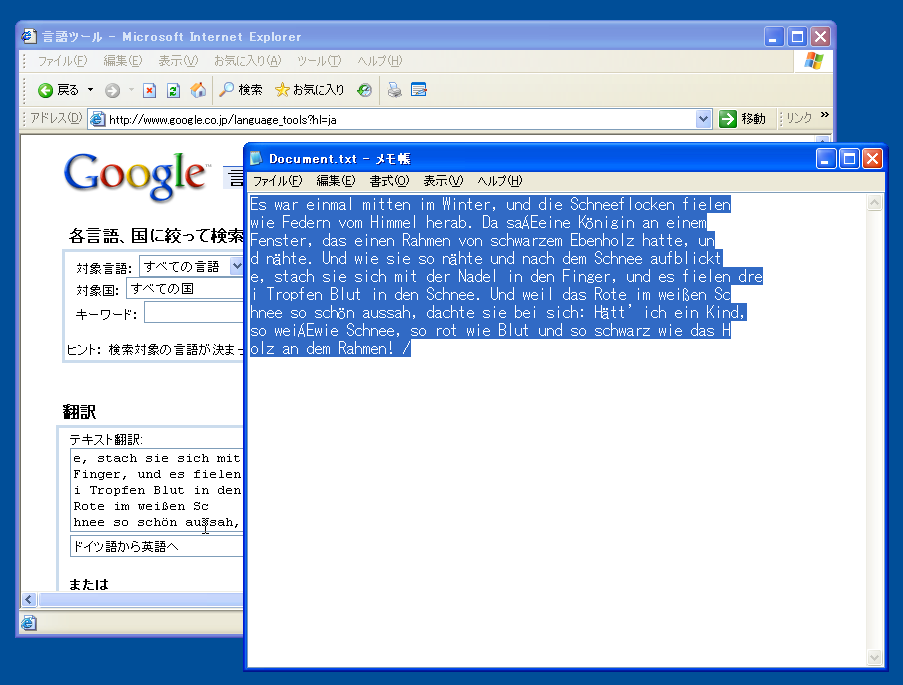
保存したテキストは、Unicode対応のテキストエディタか、ブラウザなどで表示すれば、正しく表示される。Googleの言語ツールのページで、翻訳テキスト入力欄にコピペして、翻訳してみよう。
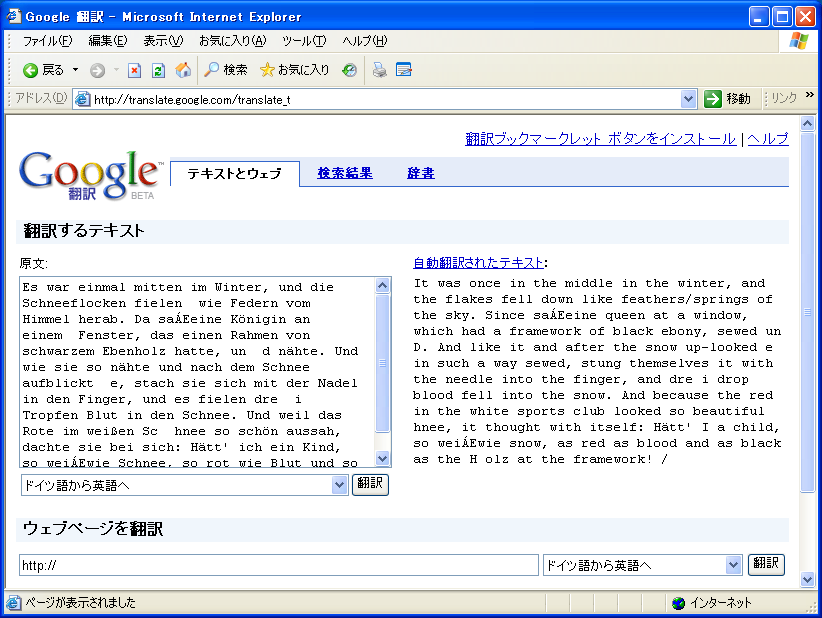
見事にドイツ語から英語に翻訳できたぞ。
 全世界1,000万以上ダウンロード超え!水分補給サポートアプリ最新作『Plant Nanny 2 - 植物ナニー2』が11/1より日本先行配信開始中
全世界1,000万以上ダウンロード超え!水分補給サポートアプリ最新作『Plant Nanny 2 - 植物ナニー2』が11/1より日本先行配信開始中 たこ焼きの洞窟にかき氷の山!散歩を習慣化する惑星探索ゲーム『Walkr』がアップデート配信&6/28までアイテムセール開始!
たこ焼きの洞窟にかき氷の山!散歩を習慣化する惑星探索ゲーム『Walkr』がアップデート配信&6/28までアイテムセール開始! 【まとめ】仮想通貨ビットコインで国内・海外問わず自由に決済や買い物ができる販売サイトを立ち上げる
【まとめ】仮想通貨ビットコインで国内・海外問わず自由に決済や買い物ができる販売サイトを立ち上げる 速報レポ! ExpressCard型地デジ録画カード「フリーオエクスプレス」
速報レポ! ExpressCard型地デジ録画カード「フリーオエクスプレス」 ブラウザ上でエクセルチックな表計算をする「Google Spreadsheets」
ブラウザ上でエクセルチックな表計算をする「Google Spreadsheets」 ボーカル音だけ消した自宅練習用のカラオケ音源を作成したい。
ボーカル音だけ消した自宅練習用のカラオケ音源を作成したい。 PT1:「BonDriver」で美麗なデジタルTVを録画しまくろう!
PT1:「BonDriver」で美麗なデジタルTVを録画しまくろう! オリジナリティあふれるケータイ着信音を作成する
オリジナリティあふれるケータイ着信音を作成する 画像ファイルの中に記載されたテキストを読み取る「GT Text」
画像ファイルの中に記載されたテキストを読み取る「GT Text」
